Java网络爬虫简介
Java网络爬虫简介
1. Web爬虫简介
Web爬虫,也称为网络爬虫或网络蜘蛛,是一种按照一定的规则,自动地、有条理地抓取互联网信息的程序或脚本。它通常用于收集数据,如网页内容、图像、视频等,并将其存储在本地或数据库中。
Web爬虫的工作原理是通过发送HTTP请求来访问目标网址,然后解析网页内容,并从网页中提取有用信息。
2. Java网络爬虫
Java网络爬虫是指使用Java语言编写的网络爬虫。Java语言是一种面向对象、编译型、平台无关的编程语言,具有健壮性、跨平台性等特点,非常适合开发网络爬虫。
3. Java网络爬虫实现
使用Java语言实现网络爬虫,可以采用以下步骤:
- 定义目标网址:首先需要定义要爬取的网站或网页的网址。
- 发送HTTP请求:使用Java的URL类和URLConnection类可以发送HTTP请求并获取网页的HTML内容。
- 解析HTML内容:使用Java的HTML解析器可以解析HTML内容,并提取有用信息。
- 存储信息:将提取的有用信息存储在本地文件或数据库中。
4. Java网络爬虫框架
为了简化网络爬虫的开发,可以采用Java网络爬虫框架。常见的Java网络爬虫框架包括:
- Jsoup:这是一个用于解析HTML和XML的库,可以轻松地从网页中提取数据。
- HttpClient:这是一个用于发送HTTP请求的库,可以方便地发送各种类型的HTTP请求。
- HtmlUnit:这是一个基于WebKit的浏览器模拟框架,可以模拟浏览器行为来抓取网页内容。
5. Java网络爬虫注意事项
在开发和使用Java网络爬虫时,需要注意以下几点:
- 遵守网站协议:不要爬取那些禁止爬取的网站。
- 控制爬取速度:不要在短时间内发送大量请求,以免被网站服务器拒绝。
- 使用用户代理:在发送HTTP请求时,可以使用用户代理来伪装自己的身份。
- 处理异常情况:在爬取过程中可能会遇到各种异常情况,需要做好处理异常的准备。
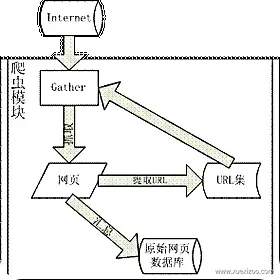
6. Java网络爬虫应用场景
Java网络爬虫可以应用于以下场景:
- 数据收集:可以抓取网页内容、图像、视频等数据,并存储在本地或数据库中。
- 信息聚合:可以将来自不同网站的信息聚合到一起,方便用户查询。
- 搜索引擎:可以抓取网页内容,并建立索引,方便用户搜索。
- 价格对比:可以抓取不同网站的产品价格,并进行对比。
- 舆情监控:可以抓取新闻、论坛、微博等网站的内容,并进行舆情分析。
阅读剩余
版权声明:
作者:小龙人
链接:https://www.xuexizoo.com/article/1759808063168069895.html
文章版权归作者所有,未经允许请勿转载。如有侵权,请发邮件联系管理员进行处理,邮箱地址:121671486@qq.com
作者:小龙人
链接:https://www.xuexizoo.com/article/1759808063168069895.html
文章版权归作者所有,未经允许请勿转载。如有侵权,请发邮件联系管理员进行处理,邮箱地址:121671486@qq.com
THE END